Only a few years ago, end-to-end speech-to-speech translation (S2ST) seemed like one of those technologies that belonged to conference talks and research papers rather than real products. When Google introduced Translatotron in 2019 or META Seamless in 2023, it was a glimpse of what might one day be possible: translating speech directly into speech, without detours through text, and even preserving the speaker’s voice. It was brilliant. It was futuristic. But almost nobody (me included) believed it would be powering consumer devices any time soon. Yet here we are.
The new Google Pixel Live Translate and Google Meet’s translated audio are built on precisely that kind of end-to-end model. What looked like distant research has quietly crossed the threshold into production. This is not merely an incremental improvement in translation quality. It represents the arrival of a fundamentally new class of real-time language technology. And, at least for some languages, it is running on devices ordinary people carry in their pockets.
From Cascaded Systems to Direct Audio-to-Audio Translation
Traditional speech translation works like a relay race: speech is turned to text, text is translated, and the target text is converted back to speech. The possible architectures are very different, from simple concatenation to advanced orchestration with reasoning steps, monitoring phases, and so on. The cascading approach has many advantages, but each step introduces delay and error. For example, a typical cascaded pipeline adds several seconds of latency by default. While this might be acceptable for one-to-many scenarios in simultaneous mode such as lectures, presentations etc., it is far too slow for natural dialogue.
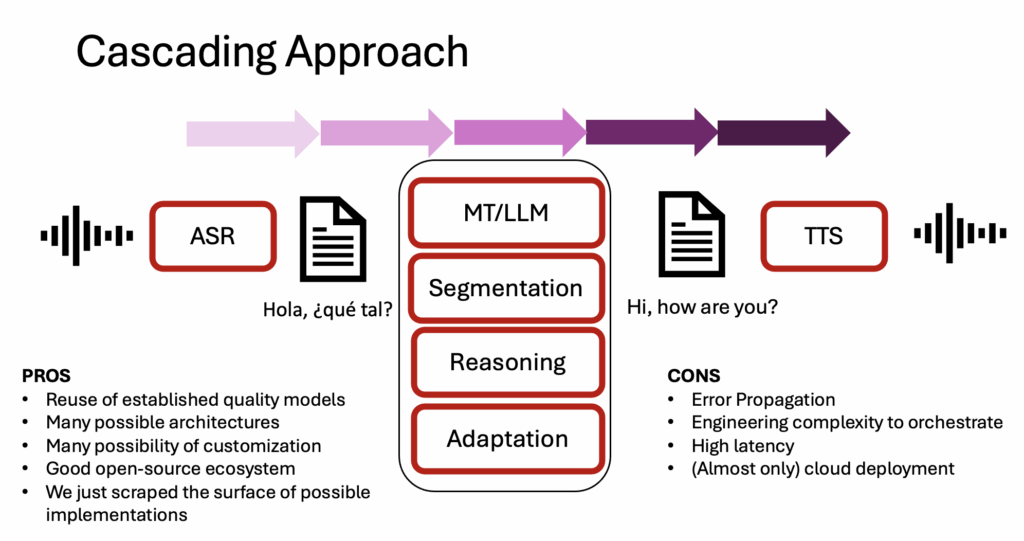
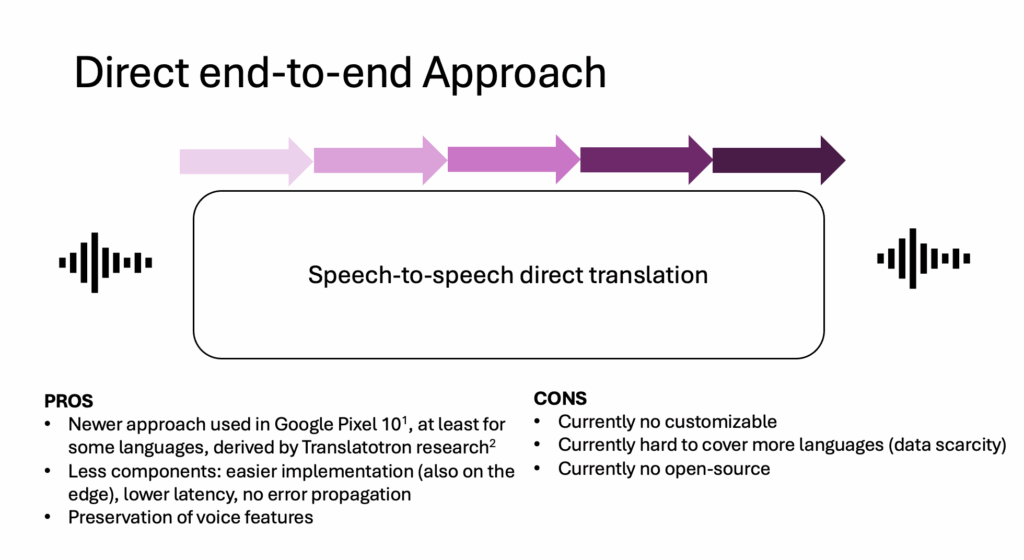
End-to-end S2ST collapses all of that. A single model listens in one language and speaks in another, producing audio tokens directly. This is why the Pixel’s translations feel different: the timing is smoother, the intonation more natural, and the voice surprisingly similar to the speaker’s own.
When me and Renato Beninatto tested the Pixel (video here), we suspected — almost reluctantly — that we were hearing an end-to-end model. The style of translation and the subtle preservation of voice qualities were telling. But we were unsure because most experts believed the technology was still in its infancy, certainly not ready for mass deployment.
In their latest technical blog, Google has now confirmed it: their system is end-to-end, streaming, personalized, and real-time. Let’s have a look at it and try to figure out the implications.
The Two-Second Breakthrough?
The headline is the two-second delay. That’s extremely close to human simultaneous interpreting. Let’s keep in mind that reality is always a bit different than announcements. But when you try it out, latency is really lower than current cascading approaches. Achieving this required innovations in data alignment, model architecture, and deployment.
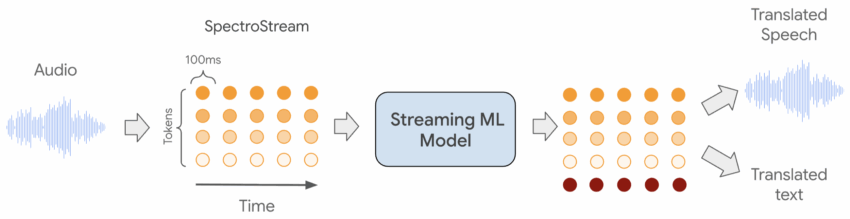
Google constructed a large-scale data pipeline to precisely align source audio with translated audio. This ensures the model learns not only what to say, but when to say it. The training data is filtered aggressively so that only examples with reliable alignment and acceptable delay remain. The system learns to stream audio, deciding on the fly when it has enough information to produce translated output.
Conversely, most commercial cascading systems wait for a end of sentence sentence boundary which adds quite a long of what I call “linguistic latency). Note that it is possible to reduce this “waiting time” to a sub-sentence level by maintaining quality, as I demonstrated here, something that we certainly see adopted in production in the near future. A streaming end-to-end system, however, waits for a few hundred milliseconds instead. This is what allows the model to maintain conversational flow instead of translating in longer blocks.
How It Fits on a Phone: Quantization and New On-Device AI Chips
One of the quiet revolutions in this story is not the model itself, but the fact that it runs on the edge. Google’s Pixel uses a combination of custom silicon (the Google Tensor G3 and now G4 chips) and advanced quantization techniques to make the model small, fast, and energy-efficient. Large S2ST models are computationally heavy; running them in real time on a mobile device was unthinkable just a few years ago.
The result is significant: quite fluent cross-lingual audio translation running entirely – however only for some languages! – on the device, with a server-side fallback in some contexts (I presume for not supported languages).
Running S2ST on the edge has some key advantages:
- avoids privacy concerns tied to cloud audio streaming (albeit when you use a telephone, like in the case of Pixel, your voice is still processed by the company on the cloud…)
- reduces latency dramatically,
- preserves user experience even with poor connectivity, and
- does not cost a penny to be run. Google give this feature for free.
Why This Matters for Interpreting
The story here is not simply that a new model works. It is that the entire set of assumptions about speech translation has changed. It is a paradigm change. End-to-end models are not “future technology” anymore. They exist, they run in real time, and they run on edge devices thanks to breakthroughs in quantization, codecs, and mobile AI hardware.
And there is another implication: speech-to-speech translation is becoming free, much as written translation became free with Google Translate and DeepL. If you can run it on your own device, the feature does not cost anything to the provider, obviously beside the R&D behind it. The quality may still fall short of what well-engineered cascading pipelines can deliver, where far more parameters can be controlled and optimised, and it may therefore remain unsuitable for many professional use cases. Yet it unmistakably signals a near future in which every phone — having already hosted a world-class chess champion — will also come equipped with its own built-in interpreter. This obviously changes the dynamic of the interpreting ecosystem.
Future trend
This technology represents a real step forward. We are entering a phase in which both approaches will drive machine interpreting, each with distinct strengths and limitations. End-to-end models offer remarkable ease of deployment — even on consumer devices — while cascaded pipelines still provide greater customisation, control and broader language coverage. End-to-end systems also deliver unmatched latency, a development that will inevitably push cascaded architectures to optimise further and adopt every advanced engineering practice available. The ability to replicate a speaker’s voice may become a decisive factor for user acceptance in some settings, whereas in professional environments a natural, neutral, and expressive synthetic voice may be more than sufficient.
As always, much will depend on time and real-world adoption patterns. Whether people will use this technology at scale remains an open question. Technical capability alone does not guarantee widespread uptake, and only the next few years will reveal how users actually integrate it into their daily lives.
Really impressive. thank you for the background.
Do you know how to use it? is there an API?
Thanks for the comment. This is my own implementation, so not direct API for this.