
I have recently focused my efforts on a major pain point for users of simultaneous speech translation systems: latency. In real-world production environments, it’s not uncommon to see systems with a delay of 8, 10, or even 12 seconds or more, which makes for a frustrating and disjointed experience. The good news is that with a new approach I’ve been developing, I’ve been able to drastically reduce this delay to an average of just 4.5 seconds. This isn’t just a theoretical improvement; it’s a real and significant leap forward. At the end of the text I uploaded a video demoing the principle.
What is Simultaneous Machine Interpreting?
Simultaneous machine interpreting, often referred to as speech-to-speech language translation, is the process where a computer system listens to speech in one language and produces a translation in another language in near real-time, without any interruptions, delivering the translation while the original is still unfolding. While the technology has advanced significantly, one of the primary challenges of AI simultaneous speech translation remains: latency1.
Latency in simultaneous machine interpreting (but this applies also to speech-to-text translation) is a combination of two key factors:
- System Latency: This is the time required for all the computational components — such as the acoustic model, language model, and translation model — to process the input and generate an output. This is a purely engineering problem and for the sake of this discussion can be approximated at around 1 second, though it varies.
- Linguistic Latency: This is the time the system must wait for the incoming speech to grow to an intelligible unit that can be accurately translated. This is a specificity of the simultaneous modality.
A common trade-off exists between latency and accuracy; a longer latency generally leads to higher translation quality. This relationship is well-documented in research (see Papi et al. 2025). A traditional solution in production is to wait for a full sentence before beginning translation. This is achieved by adding a punctuation layer to the output of the Automatic Speech Recognition (ASR) system. When a full stop is predicted, the system begins to translate. Since the translation is based on a complete sentence, the quality is at its maximum.
However, this approach leads to a significant problem with latency. Since the system’s total latency is the sum of system latency and linguistic latency, for a five-word sentence, the linguistic latency could be around 2.5 seconds, resulting in a total latency of approximately 3.5 seconds (2.5 + 1). This is acceptable by the users. For a longer 20-word sentence, the linguistic latency could be 10 seconds, pushing the total latency to an impressive 11 seconds. This creates a very long delay for the user that complain of a detachment from what is happening in the event. Let’s be clear. Traditional systems are useful even with this kind of peaks in latency, but the user experience will grow a lot if it would be possible to reduce latency by maintaining the same level of quality.
Many attempts have been studied in literature to reduce latency. While breaking down the sentence into smaller pieces using techniques like k-waits can drastically reduce latency, it comes at a great cost. The translations are done in isolation by neural machine engines, leading to an exponential decrease in the quality of the individual parts. Reconstructing these parts into a coherent sequence often results in a nonsensical output.
A New Approach with LLMs for Simultaneous Speech Translation
This challenge is now being addressed with the use of Large Language Models (LLMs) for the translation task. First paper reports promising results in using LLM for simultaneous speech translation (see Ouyung et al. 2024; Deng et al. 2025). LLMs have the ability to use co-text (the previous parts of the speech) to reconstruct and generate a continuous stream of language in real-time (see my old article). By teaching the LLM an appropriate technique using cues from the ASR engine and its own capability of “language molding”, it’s now possible to imitate to some extension the famous chunking techniques used by human interpreters, who progressively process incoming speech. Chunking in simultaneous interpreting involves breaking a complex, lengthy flow of speech into smaller, manageable segments of meaning, called “chunks”, to reduce cognitive load and improve accuracy and fluency. Interpreters identify these units, often a complete thought or part of an idea, to process and render them into the target language, managing the cognitive demands of real-time processing and producing clear, well-structured output (see Gile D. 2009; Seeber K. G. 2013).
This imitation is not an exact replication. Let’s call it inspiration. While human interpreters use a multitude of conscious and unconscious cues to split speech into digestible chunks, the AI system uses different cues, such as punctuation and grammatical markers. They are much basic in form, but can be seen as proxies for some of the cues used by humans. The process itself is different, but the inspiration is the same. Importantly, this approach is not based on a fixed policy but varies depending on the input.
With this technique, the average latency I could measure on an extensive evaluation corpus is around 4.5 seconds (for English), which is quite comparable to the average ear-voice-span of human interpreters (see Fig. 1 for an example). Most importantly, the quality of the translation suffers very little. The result is to have more shorter chunks of translation, well connected at a grammatical and semantic level, with no rewriting (the tendency of streaming services to correct themselves) that can be then vocalized in a streaming.
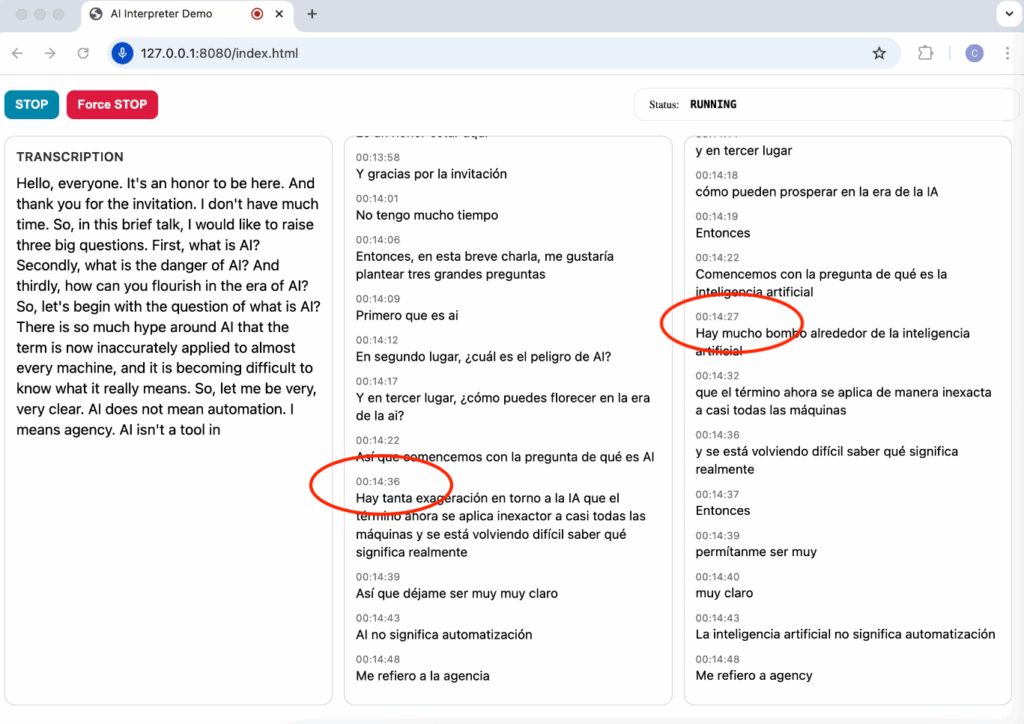
For the first time, it has become possible to significantly decrease latency in simultaneous speech translation while maintaining consistent quality. There are, however, a few caveats. Sometimes the translated sentence is not 100% grammatically correct as the LLM’s appending mechanisms reach their limits and the system is unable to convey the full meaning without breaking the rules. This is also a typical challenge for human interpreters, especially during difficult speeches (cognitive overload). Human interpreters have ways to compensate, such as modulating their voice (pitch, intonation) or self-correcting, but these are still far (very far) from being mastered by machine systems. Humans are still unbeatable in these subtle yet crucial sub-tasks of interpreting.
The first video with timestamps demonstrate the different behavior between a traditional system and this LLM-based approach. The second video shows ho it could also be used to have quite dynamic subtitles in high quality and still with a very low latency and, importantly, no flickering, i.e. no corrections one the fragment is emitted.
Bibliography
Deng, K., Chen, W., Chen, X., Woodland, P.C., 2025. SimulS2S-LLM: Unlocking Simultaneous Inference of Speech LLMs for Speech-to-Speech Translation. https://doi.org/10.48550/arXiv.2504.15509
Gile, D. (2009). Basic Concepts and Models for Interpreter and Translator Training. Amsterdam: John Benjamins Publishing Company.
Ouyang, S., Xu, X., Dandekar, C., Li, L., 2024. FASST: Fast LLM-based Simultaneous Speech Translation. https://doi.org/10.48550/arXiv.2408.09430
Papi S., Polák P., Macháček D., Bojar O. (2025). How “Real” is Your Real-Time Simultaneous Speech-to-Text Translation System?. Transactions of the Association for Computational Linguistics; 13 281–313. doi: https://doi.org/10.1162/tacl_a_00740
Seeber, K. G. (2013). Cognitive load in simultaneous interpreting measures and methods. Target 25, 18–32. doi: 10.1075/target.25.1.03see
- Latency, in the sense meant in this article, is also referred as ear-voice-span in Interpreting Studies. ↩︎
1 thought on “Reducing Latency in Simultaneous Machine Interpreting with LLMs”