
We hear this word everywhere, especially, but not only, from its detractors: AI hallucinations. The word has entered everyday language, often used as a catch-all explanation when an AI system confidently says something wrong. In the most general sense, a hallucination refers to a situation in which an AI system produces information that is not grounded in its input, training data, or external reality, yet presents it as if it were correct. But what does that really mean for us? Is a hallucination just a bug, i.e. an annoying error that will disappear with the next, better model? Or is it something deeper, something structural?
This question matters more than it seems. Because depending on the answer, we may need to radically change how we design, use, and trust AI systems. This is true for general-purpose applications, like chatbots, but it becomes especially critical in translation and interpreting. An automated translation system that invents content, rather than translating what was actually said, is, needless to say, unreliable. Such behavior would severely limit its safe deployment, especially, though not exclusively, in high-stakes settings.
To better understand hallucinations, and the role they have in interpreting, I believe it helps to step away from headlines, both of those saying like a mantra that AI is controllable and those who say AI is by definition unreliable, and look at a dense but illuminating academic analysis by philosopher Luciano Floridi and his co-authors. Their work offers a conceptual map of how humans and large language models (LLMs) relate to the world, and why hallucinations are not accidental failures, but an inevitable consequence of how these systems are built.
Why LLMs Speak Plausibly but Not Truthfully
Two Paths to the World
Floridi’s paper begins with a deceptively simple diagram (fig.1). It shows two parallel paths for answering a question about the world. The first is the human path. A person, call her H, is asked a question. She brings to it her epistemic situation: everything she already knows, believes, remembers, and has experienced. She may consult external sources, such as books, articles, websites, what the paper calls content (C). From this, she produces statements about the real world (W), i.e. the expected answer.
Crucially, humans have something more than this basic workflow. There is a direct link from H to W. Floridi labels it X. That arrow represents direct access to reality: perception, experience, bodily interaction, and the ability to check claims against the world itself. I know snow is cold not only because I have read it, but because I have touched it. I can look out of the window. I can test, verify, doubt.
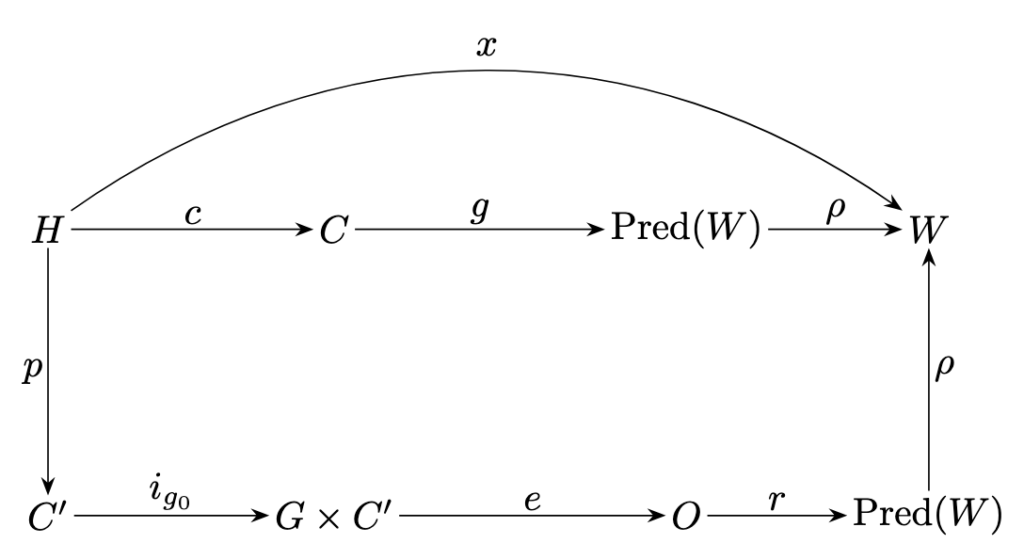
The second path is the LLM path. under the current AI paradigm. The same question is transformed into a prompt. The model, call it G, processes that prompt and produces an output (O), a string of words, which represent a prediction about the world, which is turn a statement about it (W), I.e. the expected answer. On the surface, the result can look strikingly similar to a human answer. In some cases, it can even be better than that.
But one thing is missing. There is no arrow X. The LLM has no direct access to the world. Its entire universe consists of human-produced content (C). It does not perceive, test, or experience reality. It only processes linguistic patterns derived from texts written by beings who do have that direct link. This absence is not a technical oversight. It is rather the core of the system’s nature. It is what we call the current AI paradigm: system based on the ability to navigate a wealth of information without having any ability to connect directly to the meaning of that information.
A New Way to Think About Hallucinations
Floridi and his colleagues propose a powerful redefinition of what it means for an AI answer to be “correct” (and conversely to be wrong). Instead of asking whether an AI gives a complete answer, they introduce the notion of soundness.
Imagine all correct human knowledge about a topic as a large circle. An AI’s answer is sound if it lies entirely inside that circle, even if it covers only part of it. This leads to a counterintuitive conclusion:
an incomplete answer is not a failure. Suppose an AI is asked: What inputs are needed for photosynthesis? If it answers: light and CO₂, it has omitted water. The answer is incomplete, but everything it says is correct. Its smaller circle lies entirely inside the larger one. According to Floridi’s criterion, this is a success.
A hallucination occurs only when the AI steps outside the circle, when it adds something that does not belong. If the AI answers: light, CO₂, and soil, it has crossed the boundary. That extra element has no grounding in reality. That is a hallucination. The key point is this: hallucinations are not about ignorance, but about stepping outside the circle of knowledge, and this is done in practical terms through inventions. This is what we call hallucinations.They are failures of coherence with human knowledge, not failures of coverage. Given this premise, we can move to the more interesting bit.
The Symbol Grounding Problem
This analysis leads directly to a classic philosophical challenge: the symbol grounding problem. Humans do not merely manipulate symbols. When I say “dog”, the word is connected to sensory memories, emotions, bodily interactions, and lived experience. In other words, meaning is grounded in the world.
As we have seen above, LLMs, by contrast, manipulate symbols that refer only to other symbols. Floridi’s paper makes a strong claim: LLMs do not solve the grounding problem, they bypass it. They do so by exploiting an enormous body of human language that is already grounded. Meaning is borrowed, not generated. Floridi uses a striking phrase: LLMs are epistemically parasitic. They live off the grounding performed by humans.
In this context, the paper identifies three grounding mechanisms that humans have and LLMs lack:
- Causal perceptual coupling – direct sensory experience of the world.
- Sensorimotor embodiment – understanding shaped by having a body that acts.
- Social and normative practices – being accountable for what one says, participating in the “game of giving and asking for reasons”.
LLMs participate in none of these. They are not responsible, cannot justify their claims, and have no stake in truth, only in plausibility. Again, this is not an error, this is how current LLM are designed. To better understand this principle, Floridi offers a powerful metaphor.
LLMs are Masters of Shadows
LLMs do not learn the structure of the world. They learn the structure of language about the world. They are like experts studying shadows on a wall. They can predict those shadows with astonishing accuracy, describe them in exquisite detail, and generalize their patterns. But they can never turn around and see the object casting the shadow. This explains why hallucinations are not bugs.
LLMs are optimized to produce the most plausible next word, not the truest statement. When a falsehood sounds right, in other words when it fits the patterns (the shaoof reality), the model has no internal mechanism to stop itself. From this perspective, waiting for a future model that “never hallucinates” is, according to Floridi, misguided. The missing arrow X cannot be patched with more data or larger models. It is a structural absence. The real challenge, Floridi concludes, is not to eliminate hallucinations, but to manage them: through system design, external verification, retrieval-augmented generation, and human oversight.
Implications for Translation and Interpreting
For a long time, translation and interpreting were considered the exclusive domain of human cognition. Today, however, highly capable machines already perform, and will do so with increasing frequency, tasks that were once thought to be the sole prerogative of human experts. This development makes a conceptual reframing unavoidable.
Current translation and interpreting systems operate, like most contemporary AI systems, in the way described by Floridi: they move from a request to a statement about the world, from C to W, without direct access to the world itself, because they lack the crucial mediating component X. In this sense, translation and interpreting can be framed as a form of question answering: given an input, the system produces an output that appears to describe or refer to the world, while remaining fundamentally detached from it.
This limitation is neither accidental nor easily overcome. Even as systems improve, their outputs will remain approximations. In practice, these approximations may be more than sufficient for the communicative needs of the parties involved, but they remain structurally constrained and, at least in principle, susceptible to hallucinations.
At the same time, if hallucinations are understood as “movements outside the circle of the known”, it seems unlikely that macro-level hallucinations (radical departures from general world knowledge) will play a dominant role in mature translation and interpreting systems, especially as their multilingual knowledge bases continue to expand. The more relevant risk lies elsewhere. Hallucinations in interpreting are better understood as a micro-level phenomenon: they arise not from a lack of general knowledge about the world, but from missing, underspecified, or misinterpreted information about the specific communicative act, its context, intentions, pragmatic constraints, or situational stakes.
Grounding Translation as a Possible Way to Reduce Hallucinations
One apparent way forward is grounding: anchoring translation and interpreting systems more directly in the world. Initial steps in this direction are already underway. In my own work, for example, I have explored the integration of visual understanding into the translation process, allowing systems to condition linguistic output on elements of the physical environment. Similar developments are emerging across AI research, often without explicit reference to translation or interpreting. Indeed, it is likely that future translation systems will not be standalone tools, but rather functionalities embedded within general-purpose multimodal systems.
Yet caution is required. Even with richer forms of grounding, still closer to anchoring than to genuine world access, these systems will remain replicas. And paradoxically, this is precisely where their strength lies. Their effectiveness does not depend on reproducing how human experts act on reality, but on achieving comparable outcomes through fundamentally different mechanisms.
Are there companies that publicly declare they work on such multimodal systems for translation/interpreting purposes? Also, whenever a interpreting/translation solution, it often seems to have been developed by engineers without aid from actual linguists. Does anyone try to marry the two worlds, IT and translation/interpreting?
There is quite a consistent part of computer science working on multimodality, albeit not directly related with translation. About companies integrating it into products, I think no, since there are other aspects that needs to be solved/improved before. I can assure you that there is also a lot of linguistic expertise in the teams developing the underlaying technologies (computer linguistics to name just a discipline), but also, surely not always, in the companies that create the final products.