
A few weeks ago, I wrote about the intellectual and practical need to develop a Turing Test for Speech Translation to measure whether AI-driven interpreting systems have achieved high level performance in real-time language translation. The proposed test would be passed only when human judges can no longer distinguish whether a translation was produced by a machine or a human interpreter.
In that article, I emphasized that current AI systems are still far from meeting such a standard. The technology is not yet mature enough even to warrant a meaningful application of the test. However, I also noted the pace of progress in this field is extraordinary, and a shift may occur sooner than expected. This leaves the pressing question that everyone wants answered: What do we mean by “soon”? That is, among others, the focus of this follow-up.
The first point to clarify is that the exact timing —whether human parity is achieved in two or twenty years— is not, in the grand scheme of things, particularly significant. Human civilization has evolved over millennia, and technological milestones, even when disruptive, are incremental on that timeline. What truly matters is not when human-level speech translation will be reached, but whether it will be reached. At this point, the only answer I can give feels almost inevitable: machines will be able to interpret speech at a human level. Although timing is of secondary importance to me, I will nonetheless indulge in a bit of forecasting or, to use a better term, speculation.
To address this more rigorously, however, I propose breaking the discussion down into three fundamental questions:
- How should we define human-level performance in interpreting?
- When can we expect AI interpreting systems to achieve this level of performance?
- Which technological approach shows the most promise for reaching human-level interpreting performance?
There is also a fourth, pressing question: the one concerning the impact of such technologies on work. I deliberately leave it out of full discussion here, as it deserves a dedicated article of its own.
1. Defining Human (and Super-Human) Level Performance
The notion of human-level performances (sometimes also dubbed human parity, or singularity1, in the words of translation entrepreneur Marco Trombetti) in interpreting is far from straightforward, as it is in many other domains. While first scientific papers starts using this concept also for speech-to-speech translation systems (Cheng et al., 2024), comparisons are not always easy, because the very ontologies of what is being compared often differ, making such comparisons inherently limited. Asking whether a bird is better at flying than an airplane illustrates this complexity: it depends on what aspects of flight you’re evaluating. The same applies to interpreting. Are we referring to elite interpreters operating under extreme cognitive and linguistic pressure? Or to the average bilingual individual facilitating everyday communication? Context matters: is the setting a high-stakes diplomatic summit or a routine medical consultation? Is the interpreting consecutive or simultaneous? And so forth. Depending on how we frame the comparison and what dimensions we choose to compare, the outcome will inevitably vary. Definitions (or lack thereof) are so important that the paper “Achieving Human Parity on Automatic Chinese to English News Translation” by Hassan et al. sparked harsh criticism in 2018.
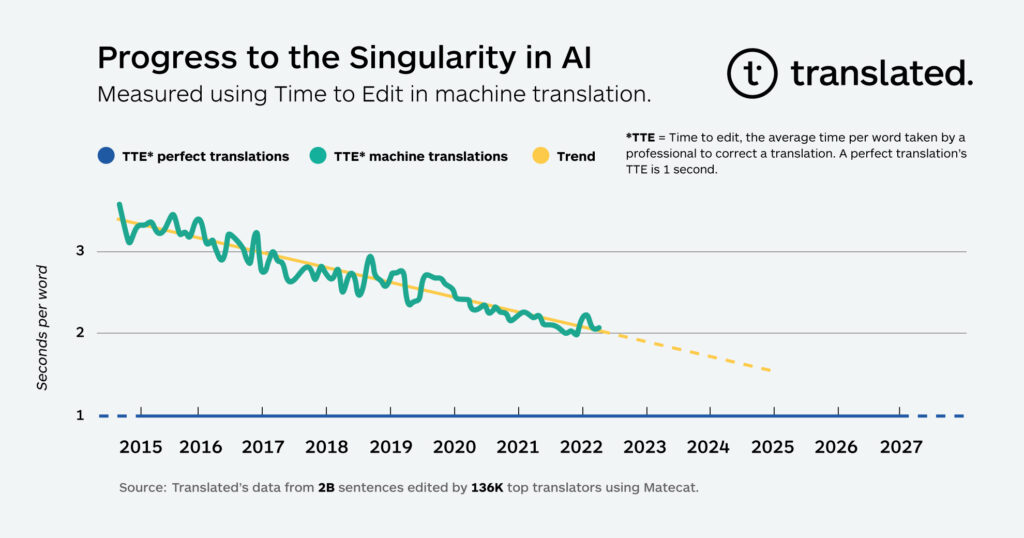
For the purpose of this discussion, I propose a pragmatic definition of human-parity: Human parity in interpreting is achieved when AI-generated interpretations are functionally accurate and perceptually acceptable—as judged by informed users—comparable to those produced by an average human interpreter within a specific real-world setting and language combination. The benchmark, therefore, is not the best human interpreter, often an idealized figure of perfection, but rather the average interpreter whose performance is considered adequate and reliable within a specific context and language combination. This aligns with common sense and corpus-based research in Interpreting Studies. Human parity, in this sense, is contextual, bounded, fit-for-purpose, and questionable.
It is important to emphasize that this definition of human-level performance differs greatly from passing a full Turing Test. For instance, a machine-generated interpretation might be functionally flawless for a given scenario yet still lack the nuances of intonation or prosody that characterize a human voice, subtleties that listeners often spontaneously detect, much like they do with professional dubbing in film. In such cases, the system may not pass the Turing Test, yet it can still achieve human-level performance. Human parity, in this context, means being “good enough” to meet established standards of accuracy, clarity, fluency, and so on. It does not require the system to be indistinguishable from a human interpreter, but rather to perform at a level comparable to that of human interpreters within a specific task and context. Crucially, “good enough” here does not imply minimal adequacy; it refers to the expected standard, also professional, in a given context.
At this point, we should also introduce the concept of super-human-level performance, which is particularly relevant in this context. Machines are not only capable of matching human performance in certain tasks; they may also surpass it. Returning to the earlier metaphor of flight: if the goal is to deliver a written message from one country to another, it becomes evident that an airplane accomplishes the task much faster and more reliably than a pigeon. And it can also carry two hundred people. It has super-capabilities compared to the bird. Similarly, super-human performance in speech translation is conceptually possible, it would imply exceeding human interpreters in terms of speed, consistency, accuracy, or even linguistic range. Take speed, for example: machines would be considered superhuman if they could reduce the delay in simultaneous interpreting to one second, compared to the typical 3 or 4 seconds for humans. Or even make it like a dubbing style. I would argue that this level of performance differs so significantly from human-level that a generalized Turing Test would no longer be applicable. Let’s just keep this possibility in mind.
2. When Will We Get There?
I have stated on several occasions that I have no doubt human-level performance, as defined above, will eventually be achieved. Based on current trends in both general AI science and engineering as well speech translation technologies, and considering the current exponential pace of advancement in language processing, I estimate that we may achieve human parity in some interpreting modalities within 2 to 5 years. This is a conservative forecast, and like any prediction, it may turn out to be completely wrong. Past experience in many domains has shown that people tend to be overoptimistic in their predictions. This might be the case here as well. As the old saying goes: only time will tell.
The timeline will probably varies by modality. Consecutive interpreting, which involves a greater delay between speaker and interpreter, is computationally simpler and likely to reach parity sooner, perhaps within two years. Simultaneous interpreting, by contrast, is far more complex, requiring real-time processing and predictive strategies. This modality may require closer to five years. Simultaneous interpreting, as performed by humans, i.e. with a very short delay, remains such a formidable challenge for machines: linguistically, cognitively, and technologically. Humans are truly masters of this compelling task.
When it comes to passing the proposed Turing Test in speech translation, where listeners are unable to discern whether the interpreter is human or machine, progress may be slower. Nonetheless, I believe the gap between the two may close more rapidly than my intuition might suggest. Functional parity could be reached relatively soon, with true indistinguishability potentially emerging thereafter.
3. Which Technology
This is yet another question without a straightforward answer. There is no doubt that the current cascading model, where speech recognition (ASR), neural machine translation (NMT), and speech synthesis are combined sequentially, is not sufficient to achieve true human-parity. While this architecture performs well in controlled scenarios and has, in some specific instances, matched professional interpreters, it lacks the flexibility and adaptability required for real-life interpreting. And interpreting in real-world meetings is, above all, a matter of flexibility: dealing with interruptions, ambiguous language, unclear references, overlapping speech, cultural components, style, intentionality, contextual awareness, and fast topic shifts. These are aspects that cascading systems, by their design, are ill-equipped to handle.
The answer lies, almost certainly, in generative AI and its remarkable capacity for contextual understanding and linguistic reasoning. Unlike traditional NMT pipelines, generative models, especially large language models (LLMs), can process and generate language with a degree of coherence, nuance, and adaptability that begins to approximate human cognitive flexibility. Experiments have already shown indistinguishibility output between humans and machines in some areas. Generative models are not merely pattern matchers; they can infer speaker intent, resolve ambiguities, and even recover gracefully from errors, which are all core traits of human interpreters. And this, without requiring any human-like intelligence (Fantinuoli, forthcoming).
In theory, the most promising approach for reaching human parity would involve truly multimodal large language models, systems that process and generate language directly from audio, without fragmenting the process into discrete, isolated steps. These models will process spoken input holistically, interpret meaning in context, and produce speech output naturally, with prosody and rhythm aligned to communicative intent (Seamless, 2025). There’s a flurry of research activity, but we are still away from this objective. In the longer term, models that also incorporate vision, for interpreting gestures, facial expressions, or shared visual references, could further enhance this capability, though such integration is still in its infancy, or practically non existent.
In the shorter term, however, more immediate progress may come from an intelligent integration of ASR systems with textual LLMs. If engineered carefully, with alignment between the output of speech recognition and the input expectations of the language model, this hybrid approach could prove sufficient to reach human parity in certain contexts, particularly in structured or semi-structured environments like medical consultations, legal depositions, or moderated discussions. These early implementations may serve as the bridge toward fully integrated, end-to-end multimodal systems. I see the scientific community currently placing strong focus on this area, and I expect experimental and commercial implementations to come soon, as I hope it is the case for robust evaluation methods.
As a side note, given the current trajectory of technological development, the true creators of the underlying technology won’t be those building the end-user applications, but rather the tech giants investing billions in general AI—or, in the shorter term, the smaller (though still substantial) players focusing on LLMs specialized in translation.
Uncertainty and Implications
Is my prediction a certainty? As I stressed at the outset: certainly not. No forecast about complex technological evolution is ever fully reliable. The only thing we truly know is that we don’t know. I may be off by several years. Yet the core sentiment remains: like many other human activities, human-like interpreting performance is within reach, and likely within the near future. Passing the Turing Test will likely follow, though on a slightly longer timeline.
The implications of achieving this milestone are profound. On the one hand, the ability to understand and be understood across languages in what will become an ubiquitous service could dramatically enhance communication, accessibility, possibly the economy, and generally speaking global collaboration, even if I argue that this will not always be the case (Fantinuoli, 2025). On the other hand, such advancements will create a larger divide between languages and cultures (see for example the gap between low and high resource languages), create many ethical questions about their usage, especially in high-stake scenarios, and ultimately challenge the interpreting profession and the institutions that train interpreters. Even if AI systems will not eliminate the need for human interpreters altogether in the short and middle term, as I try to make clear every time I talk about this topic (there are several compelling reasons for this), they will undoubtedly disrupt significant parts of the market. And this, starting from the anxiety it creates, long before any practical impact, is arguably the saddest part of technological advancement.
Bibliography
Cheng, S., Huang, Z., Ko, T., Li, H., Peng, N., Xu, L., Zhang, Q., 2024. Towards Achieving Human Parity on End-to-end Simultaneous Speech Translation via LLM Agent. https://doi.org/10.48550/arXiv.2407.21646
Fantinuoli C. “Machine Interpreting”. In Sabine Braun, Elena Davitti and Tomasz Korybski (ed.) Routledge Handbook of Interpreting and Technology. Routledge (2025)
Hassan, H., Aue, A., Chen, C., Chowdhary, V., Clark, J., Federmann, C., Huang, X., Junczys-Dowmunt, M., Lewis, W., Li, M., Liu, S., Liu, T.-Y., Luo, R., Menezes, A., Qin, T., Seide, F., Tan, X., Tian, F., Wu, L., Wu, S., Xia, Y., Zhang, D., Zhang, Z., Zhou, M., 2018. Achieving Human Parity on Automatic Chinese to English News Translation. https://doi.org/10.48550/ARXIV.1803.05567
SEAMLESS Communication Team. Joint speech and text machine translation for up to 100 languages. Nature 637, 587–593 (2025). https://doi.org/10.1038/s41586-024-08359-z
- The definition of singularity given by Translated is quite intriguing: “This is the point of singularity at which the time top professionals spend checking a translation produced by the MT is not different from the time spent checking a translation produced by their colleagues which doesn’t require any editing.” ↩︎
5 thoughts on “Human-Parity in AI Interpreting”